


2018 School Spending Survey Report
Gale Launches Digital Scholar Lab
Following two years in development, Gale launched its Digital Scholar Lab (DSL), a cloud-based text mining and natural language processing solution that facilitates analysis of raw text data (optical character recognition/OCR text) from 160 million pages of Gale Primary Sources content.
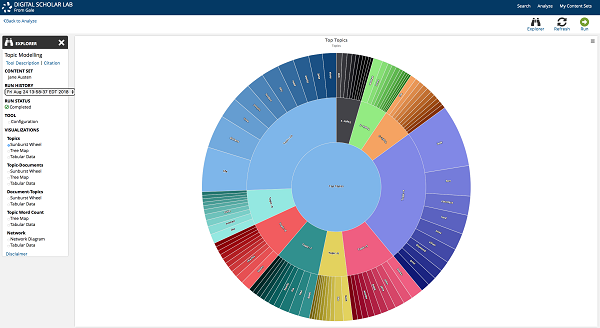 Following two years in development, Gale last week launched its Digital Scholar Lab (DSL), a cloud-based text mining and natural language processing solution that facilitates analysis of raw text data (optical character recognition/OCR text) from 160 million pages of Gale Primary Sources content. Combining commonly used open source algorithms and programs such as MALLET (MAchine Learning for LanguagE Toolkit) with proprietary tools, DSL is designed to enable students and researchers to generate data sets, utilize integrated data visualization tools, download and share those data sets and visualizations, and organize research for long-term projects.
Following two years in development, Gale last week launched its Digital Scholar Lab (DSL), a cloud-based text mining and natural language processing solution that facilitates analysis of raw text data (optical character recognition/OCR text) from 160 million pages of Gale Primary Sources content. Combining commonly used open source algorithms and programs such as MALLET (MAchine Learning for LanguagE Toolkit) with proprietary tools, DSL is designed to enable students and researchers to generate data sets, utilize integrated data visualization tools, download and share those data sets and visualizations, and organize research for long-term projects.
When researchers start a text analysis project, one of the first challenges is often finding an appropriate content set, noted Marc Cormier, Gale’s director of product management for the humanities.
“There are a number of open source content sets that you can use, but picking open source and freely available doesn’t really reflect the nature of the content need you might have…. In this case, we wanted to break down that barrier by providing all of the raw data from Gale’s content and digital collections in this one place,” he said. “Users, including scholars, librarians, graduate students, etc., can now search for and find content from Gale Primary Sources, create a custom corpus of that content that suits their research needs, and then process that content through some of the open source tools that we’ve included in [DSL] that drive visualizations that they interpret and publish.”
Introduced in 2016 as a proof-of-concept version primarily targeted at high-level researchers and postdocs, Gale began adding visualization tools and making DSL more user friendly in 2017. This year, extensive UX testing in the United States and markets including Australia and the United Kingdom helped refine the production version launched this week. Throughout the development process, a primary goal was creating a platform that makes text mining and data visualization approachable.
“We heard along the way…how much [faculty] would like to use it in the classroom,” Cormier said. DSL “does, to a great degree, make sense of some of the difficulties that a digital scholar runs into along the way. It’s not just about the difficulty in creating content sets, it’s more about ‘where do I start?’”
DSL’s home page features a prominent search bar, as well as three callouts inviting returning users to “Build your corpus,” “Analyze your documents,” and “Manage and share” documents and visualizations. Users can be authenticated via their Google Drive or Microsoft OneDrive accounts. “We didn’t want to pass on yet another set of credentials for a user to remember…. They also serve as saving mechanisms for content that you create in [DSL].”
A basic search—which searches all content text fields including captions, titles, body text, etc. excluding front and back matter—directs users to a search results page similar to Gale’s other Primary Sources products, where users can apply search limiters, search within their results, or browse the OCR text surfaced in each result. Throughout the interface, users can access context-sensitive modal boxes that present detailed definitions/explanations of key topics such as OCR, for example.
Specific results or a range of results (using limiters such as publication type or date range) can be selected to create a custom content set, and then analyze the set using DSL’s integrated tools, which enable sentiment analysis, topic modeling, parts of speech tagging, Ngram analysis, named entity recognition, clustering, and term frequency analysis.
These tools generate tabular output, as well as a variety of visualization options appropriate to each type of analysis, including graphs, sunburst wheels, tree maps, network diagrams, and more. Here, the informational modal boxes will offer users a description of the tool and underlying algorithm that was used to generate their results, as well as an explanation of sentiment analysis as a concept, for example.
While the Digital Scholar Lab can facilitate complex analysis, Cormier said that Gale believes the platform’s ease of use will also help reintroduce library resources to both faculty and students. They’ve aimed to create “not only something that a postdoc would find useful, but also one that a postdoc could use to teach digital humanities courses and text mining to undergrads,” he said.
“The conversation always comes down to content. If you think about content in the library today, one of the biggest barriers to that content being used in digital scholarship is raising awareness of [those resources] with faculty, students, etc.,” Cormier said. “It’s a different type of use case entirely—data visualization and textual analysis versus close reading, which is what we’ve typically supported with Gale Primary Sources.”

Added To Cart
RELATED


RECOMMENDED


TECHNOLOGY

ALREADY A SUBSCRIBER? LOG IN
We are currently offering this content for free. Sign up now to activate your personal profile, where you can save articles for future viewing
ALREADY A SUBSCRIBER? LOG IN
Thank you for visiting.
We’ve noticed you are using a private browser. To continue, please log in or create an account.
Add Comment :-
Comment Policy:
Comment should not be empty !!!